
1. Актуализация инновационных разработок и подходов к детектированию аномального поведения респондента:
Известное утверждение, что человеческое естество склонно к намеренному высказыванию ложных утверждений, искажения информации, дезинформации. Испокон веков задача “вывести на чистую воду” и выяснить истину была одной из важных и сложных процессов. Для выявления истины прибегали к необходимости свидетельства слов и действий третьих лиц. В современном мире для решения данной задачи используют несколько устройств, таких как полиграф, измерение потоотделения и частоты дыхания, датчик сердцебиения и монитор артериального давления. В последнее десятилетие с развитием науки в области изучения искусственного интеллекта, используют технологии компьютерного зрения, фиксируя микроизменения мимики лица респондента, расширения зрачков, измерения температуры области глаз, частоты моргания глаз, изменения направления взгляда и замера динамики изменения эмоций лица испытуемого [1].
Для задач детектирования ложной информации, чаще всего используется полиграф с высокой точностью обнаружения лжи от 81 до 91% (Гаджоли, 2018) [2]. Для функционирования такого полиграфа требуется, чтобы допрос и интерпретацию результатов проводил опытный интервьюер.
В начале 21 века технологии детектирования ложного высказывания реагировали в основном на изменение температуры вокруг глаз. Данные модели полиграфа были инновационными для времен 2000 годов, так как считывали биометрические данные с человека бесконтактно и не требовали присутствия специально обученных психофизиологов [3]. Инновационность подхода заключалась в том, что при испытывании психического дискомфорта (страх, испуг, лукавство и дезинформация), у испытуемого повышается внутриглазное давление. Это сопровождается повышением температуры вокруг глаз из-за прилива крови. Точность данного метода менее 80% в связи с рядом недостатков, к которым можно отнести влияние неподконтрольных факторов, как например, до начала интервью употребление в пищу продуктов, повышающих общую температуру тела.
На сегодняшний день существуют ряд устройств: корейский полиграф “Трастер” [4], универсальный компьютерный полиграф “Диагноз-01”, улавливающие колебания волн звука в голосе с выявлением “предательской дрожи” вне зависимости от языка говорящих. Недостатком данных устройств является их дороговизна и необходимость установления физического контакта с испытуемым.
Обман - сложное человеческое поведение, при котором субъекты пытаются подавить свои настоящие эмоции, выражения лица, манеру общения. В связи с тем, что технологии искусственного интеллекта развиваются, подходы к детектированию обманчивых выражении на основе старых аппаратов становятся не актуальными. Исходя из этого, ниже представлены исследования, в которых авторы используют различные данные и методы для обнаружения обманчивого поведения с помощью алгоритмов искусственного интеллекта.
Для решения задачи выявления обманчивого выражения в исследовании [5] авторы используют трансферное обучение. Целью трансферного обучение является применение знаний, полученные из одной задачи, к другой целевой задаче. Основной проблемой выявления обманчивого выражения в машинном обучении является нехватка размеченных данных. Для решения этой проблемы авторы воспользовались методом “Выравнивание подпространства” (ВП) (Subspace Alignment (SA)) и с классификатором k-ближайших соседей КБС. ВП адаптирует аудиовизуальные представления лжи с наборами данных, которые были сделаны в лабораторных условиях [6] для обнаружения обмана в реальных ситуациях. Для решения целевой задачи был выбран общедоступный набор видео данных о людях в 121 реальной судебной ситуации (61 для обманчивого класса и 60 для правдивого класса) [7]. Извлечение характеристик происходит с помощью инструментов OpenSmile [8], OpenFace [9] и функции ExeMaps, МЧКК. Характеристика – это независимые переменные, свойство объекта. Программное обеспечение OpenSmile используется для автоматического извлечения характеристик из аудио сигналов, также OpenFace для извлечения визуальных характеристик.
Точность данной модели достигла точности (Accuracy ACC) 74%, Площадь под кривой точного отзыва ППК 75% и Ф1-оценка 73%. Это исследование демонстрирует потенциал внедрения обучения на основе ВП для моделирования обмана и другого социального поведения в реальных условиях с дефицитом размеченных данных.
В исследовании [10] используется мультимодальный подход к обучению. Мультимодальное машинное обучение применяется для обработки информации из нескольких источников. К примеру, изображение, видеозапись, аудиозапись и текст. В качестве набора данных используется [7]. Авторы воспользовались алгоритмом глубокой сверточной нейронной сети СНС для извлечения характеристик и для дальнейшего обучения.
Визуальные характеристики извлекаются из видео с помощью 3D CNN [11]. Наилучшие результаты были получены с использованием 10-слойной архитектуры. Также, для извлечения определенных характеристик из текста была использована модель СНС. Каждое высказывание представляется в виде вектора объединения составляющих слов. Звуковые характеристики, такие как высота тона и интенсивность голоса, извлекаются с помощью программного обеспечения OpenSmile [8].
Для мультимодального слияния было использовано 2 метода: раннее слияние и позднее слияние. При слиянии на раннем этапе характеристики извлекаются из входных данных. Затем характеристики объединяются и передаются в классификатор. Этот метод использует корреляцию между несколькими характеристиками на ранней стадии, что часто приводит к лучшему выполнению задачи. В позднем слиянии одномодальные классификаторы используются для определения прогноза по каждому типу данных. Затем локальные прогнозы объединяются в единый вектор, который далее классифицируется для получения окончательного решения. Результаты исследования одномодального и мультимодального классификатора показаны в таблицах 1,2.

В исследовании [12] рассмотрен подход, основанный на мультимодальных данных, таких как аудио, текстовые, видео и невербальные аспекты. Авторы использовали набор данных [7]. Характеристики в видеозаписи на основе 3D и характеристики в тексте извлекаются с помощью глубокой сверточной нейронной сети ГСНС. Звуковые характеристики извлекаются с помощью OpenSmile [8]. Предложена аудиосистема, которая использует коэффициенты Кепстрала и дискриминантном анализе ядра спектральной регрессии. Невербальные признаки классифицируются с помощью классификатора AdaBoost, в то время как в текстовой системе используются классификатор линейный метод опорных векторов (МОВ). Набор данных также предоставляет ручные метки 39 различных вербальных и невербальных сигналов. Визуальные признаки, основанные на 2D-моделях внешнего вида [13], используются для захвата микродвижений от моргания глаз, движения бровей, появления морщин и движения рта. Исходя из полученных результатов, на выходе используется метод “правило большинства”. Предложенные методы показывают наилучшую производительность при Правильном оценке классификации” ПОК (Correct Classification Rate CCR) = 97%.

В исследовании [14] используется функция под названием "Функция трансформации эмоций" (ФТЭ). ФТЭфункция преобразования эмоций для анализа обнаружения обмана с ограниченными данными. ФТЭ содержит информацию как из пространственного, так и из временного измерения одновременно. Для обучения был взят [7] набор данных. Авторы конвертировали видеофрагменты в кадры и использовали двойной детектор лиц [15] для обнаружения и выровняйте лица в видеозаписях. Архитектура предлагаемых методов, содержит два этапа: этап распознавания эмоций и этап извлечения признаков трансформации эмоций. ФТЭ можно описать как изменение между семью универсальными выражениями лица (например, счастье, печаль, страх, гнев, удивление, отвращение и нейтральность). Прежде всего, авторы используют современный алгоритм распознавания выражений лица [16]. Были проведены эксперименты по классификации случайного леса (СЛ), по методу опорных векторов (МОВ) и по дерево решений (ДР). Результаты эксперимента:

В исследовании [17] представляется система для скрытого автоматического обнаружения обманчивых выражении с наборами данных [7]. Система использует классификаторы, которые предсказывают микровыражения человека с помощью кодирования вектора Фишера. Детекторы микровыражений обучаются с использованием МОВ с линейным ядром. Использованы функции Улучшенная плотная траектория (УПТ), которые широко использовались для распознавания действий, также очень хорошо предсказывают обман в видео. Для извлечения характеристик в аудиофайлах, авторы воспользовались Мел-частотным кепстральным коэффициентом (МЧКК). Система автоматического обнаружения обмана состоит из 3 этапов: мультимодальное извлечение признаков, кодирование признаков и классификация. Используя различные классификаторы, такие как, Лагранжева машина опорных векторов Л-МОВ, Машина опорных векторов K-средних К-МОВ, Дерево решений ДР, Случайный лес СЛ и Логистическая регрессия ЛР, модель получила наилучшую точность “Площадь под кривой точного отзыва” ППК 0.922.
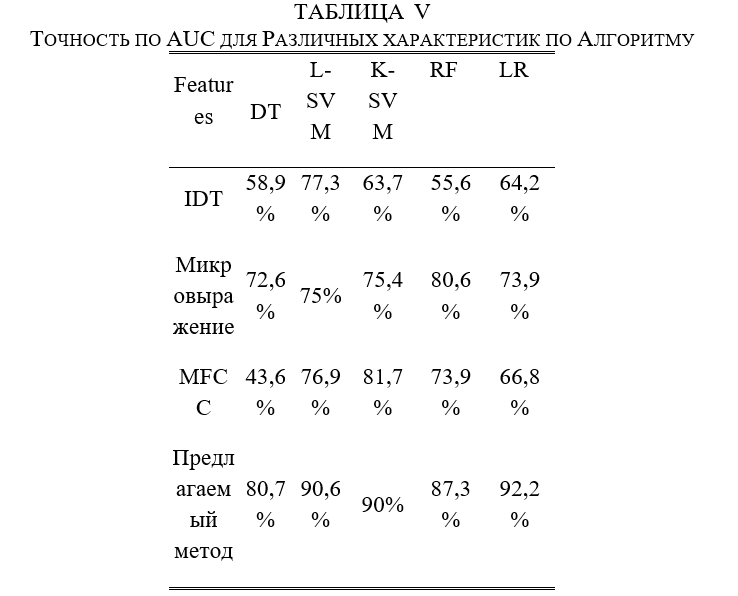
Таким образом, рассмотрены различные методы для задачи детектирования обманчивых выражений. Полученные результаты по приведенным исследованиям показаны в таблице 6.

В таблице 6 показано, что использование только аудио и видео данных недостаточно для получения высокого результата. В связи с этим, в дальнейшем планируется использование методов и алгоритмов для получения модели с наилучшим результатом, а также будут собраны данные для расширения возможности модели для задачи обнаружения обманчивых выражений.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
[1] Г. В. Наталья, “Психологические аспекты распознавания лжи”, Научно-методический электронный журнал «Концепт», 2015, Т. 13, С. 2936–2940.
[2] A. Gaggioli, “Beyond the truth machine: emerging technologies for lie detection”, Cyberpsychol, Behav. Soc. Network. 21, 2018, P. 144, DOI: doi.org/10.1089/cyber.2018.29102.csi.
[3] С. А. Виктор, “Интересные факты о полиграфе (детекторе лжи). Детектор лжи”, История полиграфа, URL: https://psyfactor.org/lib/polygraph-2.htm (дата обращения: 25.11.2021).
[4] M. Saito, “Lie detection infiltrating everyday life”, The Japan Times, URL: https://www.japantimes.co.jp/life/2002/04/25/digital/lie-detection-infiltrating-everyday-life/ (дата обращения 25.11.2021).
[5] M. Leena, M. Maja, “Unsupervised Audio-Visual Subspace Alignment for High-Stakes Deception Detection”, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021.
[6] T. Sen, “Automated dyadic data recorder (addr) framework and analysis of facial cues in deceptive communication”, ACM Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 1, no. 4, Jan. 2018.
[7] V. Perez-Rosas, “Deception detection using real- life trial data”, ACM International Conference on Multimodal Interaction (ICMI), 2015, p. 59–66.
[8] F. Eyben, F. Weninger, F. Gross, and B. Schuller, “Recent developments in opensmile, the munich open-source multimedia feature extractor”, Proceedings of the 21st ACM international conference on Multimedia, ACM, 2013, pp. 835–838.
[9] T. Baltrusaitis, A. Zadeh, Y. C. Lim, and L. Morency. “Openface 2.0: Facial behavior analysis toolkit”, IEEE International Conference on Automatic Face Gesture Recognition (FG), 2018, pp. 59–66.
[10] M. Gogate, A. Adeel, A. Hussain, “Deep learning driven multimodal fusion for automated deception detection”, IEEE Symposium Series on Computational Intelligence (SSCI), 2017.
[11] S. Ji, W. Xu, M. Yang, and K. Yu, “3d convolutional neural networks for human action recognition”, IEEE transactions on pattern analysis and machine intelligence, 2013, vol. 35, no. 1, pp. 221–231.
[12] S. Venkatesh, R. Ramachandra, P. Bours, “Robust Algorithm for Multimodal Deception Detection”, IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), 2019.
[13] L. Su and M. Levine, “Does lie to me lie to you? an evaluation of facial clues to high-stakes deception”, Computer Vision and Image Understanding, 147:52 – 68, 2016.
[14] J. Yang, G. Liu, C. Scott, H. Huang, “Emotion Transformation Feature: Novel Feature For Deception Detection In Videos”, IEEE International Conference on Image Processing (ICIP), 2020.
[15] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li, and F. Huang, “DSFD: Dual shot face detector”, Proc. IEEE CVPR, Long Beach, USA, Jun. 2019, pp. 5060–5069.
[16] D. Meng, X. Peng, K. Wang, and Y. Qiao, “Frame attention networks for facial expression recognition in videos”, Proc. IEEE ICIP. Taipei, Taiwan, Sept. 2019, pp. 3866–3870.
[17] Z. Wu, B. Singh, L. S. Davis, V. S. Subrahmanian. “Deception Detection in Videos”, PKP Publishing Services, 2018.
2. Сбор, обработка и анализ существующих наборов данных по проблеме детектирования истинного и (или) ложного высказывания респондента
При определении поведенческих признаков человека для выявления истинного или ложного высказывания в настоящее время стали обращать внимание на выражение глаз, голос, жестикуляцию и пр. На протяжении последних десятилетий исследуются наборы данных, позволяющие регистрировать вербальные и невербальные характеристики речи респондента. Исследовательской группой были проведены сбор, обработка и анализ восьми существующих наборов данных по проблеме детектирования истинных и (или) ложных высказываний.
I База данных «Box of Lies»
Ученые университетов “University College London”, “University of Michigan, Ann Arbor” Феликс Сольднер, Вероника Перес-Росас и Рада Михальча создали мультимодальный набор данных, содержащий вербальные и невербальные аннотации [1]. Набор данных содержит 25 общедоступных видеороликов из ток шоу “Box of Lies” (“Ящик лжи”, США). Это полный комплект видео длительностью 2 часа 24 минуты. В экспериментах участвуют 26 респондентов (20 женщин и 6 мужчин). Средняя продолжительность каждого видео составляет 6 минут и содержит около 3 раундов. Тем не менее, длительность каждого раунда зависит от баллов участников и от добавочного времени для дополнительных раундов. В полном видеосете участники играют 68 раундов (29 правдивых и 39 обманчивых).
II Мультимодальный набор данных по обнаружению обмана
Исследователи университетов “University of North Texas”, “University of Michigan” Вероника Перес-Росас, Рада Михалча, Алексис Нарваес, Михай Бурзо создали мультимодальный набор данных обмана на основе физиологических характеристик, тепловых измерений и визуальных реакций [2]. Детально набор данных включает в себя визуальные, акустические, физиологические и тепловые модальности. В экспериментах участвуют 30 респондентов (5 женщин и 25 мужчин). Все участники высказались на английском языке. Участники имеют возрастной диапазон от 22 до 38 лет. Для сбора физиологических данных исследователи использовали четыре различных датчика: пульс объема крови (датчик BVP), проводимость кожи (датчик SC), температуру кожи (датчик T) и брюшное дыхание (датчик BR). Для визуальных реакций они использовали две обычные веб-камеры: Quick Cam Orbit AF Logitech и HD webcam C525, каждая с максимальным разрешением 980x720 пикселей. Для определения тепловых реакций использовалась тепловизионная камера FLIR Thermovision A40 с разрешением 340x240.
III Bag of Lies: мультимодальный набор данных для обнаружения обмана
Ученые университета “IIT-Delhi” В. Гупта, М. Агарвал, М. Арора, Т. Чакраборти, Р. Сингх и М. Ватса представили мультимодальный набор данных “Bag of Lies” (“Мешок лжи”) [3]. Набор данных состоит из нескольких модальностей, таких как видео, аудио, ЭЭГ и зрительный контакт. В экспериментах участвуют 35 респондентов (10 женщин и 20 мужчин). Все участники владеют английским языком. Набор данных содержит в общей сложности 325 аннотированных записей, состоящих из 162 лживых и 163 истинных высказываний. Продолжительность записей варьируется от 3-5 секунд до 42 секунд. Для записи видео и аудио участников использовалась обычная камера и микрофон в смартфоне. Для сбора данных ЭЭГ использовалась 14-канальная гарнитура Emotiv EPOC+EEG (беспроводная связь), а для сбора данных о зрительном контакте использовался Gazepoint GP3 Eye Tracker. Кроме того, для использования в эксперименте было собрано 21 отчетливых, содержательных и описательных кадров.
IV Обнаружение лжи с высокой вероятностью по выражению лица
Исследователи университета “McGill University” Линь Су и Мартин Д. Левин собрали собственную базу данных, полученную на основе ситуаций по обнаружению лжи с высокой вероятностью [4]. Набор данных содержит 324 видеоматериала, собранных в ситуациях лжи с высокой вероятностью. Из 324 видеоклипов: 51,23% клипов содержат виновных подозреваемых, тогда как 48,77% - невиновные подозреваемые. Средняя продолжительность видеоклипов составляет 20 секунд. Отличаясь от большинства существующих баз данных, этот набор совершенно уникальный: (1) Условия освещения, также как и само освещение подбирались значительно более сложно и изменчиво. (2) Отсутствие прямых указаний в отношении положения головы и внешнего вида подозреваемых. (3) Выражение лица (мимика) полностью не наигранное, соответствует реальной обстановке.
V База данных обнаружения обмана Университета Майами
Исследователи университета “Miami University” Lloyd, E.P., Deska, J.C., Hugenberg, K. собрали базу данных обнаружения обмана Университета Майами (MU3D - Miami University Deception Detection Database) [5]. MU3D - это бесплатный ресурс, содержащий 320 видео. 80 участников (20 чернокожих женщин, 20 чернокожих мужчин, 20 белых женщин и 20 белых мужчин) высказали правду и ложь о своих социальных отношениях. Участники имеют возрастной диапазон от 18 до 26 лет. Каждая задача включала четыре различные записи (т.е. положительная правда, негативная правда, позитивная ложь, негативная ложь), в результате которых получились 320 записей, охватывающих полностью целевую расу, целевую сексуальную ориентацию, особенность артикуляций и правдивость изложений. Записи были предоставлены с использованием веб-камеры c525 Logitech HD Webcam с разрешением видео 1 280 × 720 и скоростью контура 30 кадров в секунду. Материалы всех записей и звука связаны с компьютером и произведены с использованием встроенного приемника.
VI База данных “Silesian”
Ученые университета “Silesian University” Радлак, Кристиан и Божек, Мацей и Смолка, Богдан создали базу данных “Silesian” («Силезская база данных обмана») [6]. Силезская база данных состоит из 101 видеозаписи. Внутри этой базы данных было закодировано более 1,1 миллиона кадров, как потенциальных подсказок, основанных на правде и способствующих избежать неправильного вывода по выявлению субъекта, говорящего правду или ложь. Записи были получены с использованием высокой камеры контроля скорости со скоростью 100 кадров в секунду при дневном свете и в контролируемой среде исследовательского центра.
VII Реальная база данных обнаружения обмана
Исследовательская группа университета “University of Michigan” Перес-Росас, Вероника и Абуэлениен, Мохамед и Михалча, Рада и Сяо, Яо и Линтон, CJ & Burzo, Mihai подготовили базу данных обнаружения обмана из реальной жизни [7]. Набор данных состоит из 121 видео (61 обманчивых и 60 правдивых пробных клипов). В экспериментах участвуют 56 респондентов (21 женщина и 35 мужчин), их возраст примерно составляет от 16 до 60 лет. Средняя продолжительность записей в наборе данных составляет 28,0 секунды. Средняя продолжительность видео составляет 27,7 секунды для лживых видеозаписей и 28,3 секунды для правдивых видеороликов. Набор данных был собран из различных открытых интерактивных медиа-источников по доступным записям судебных слушаний, в которых вполне приемлемо можно было наблюдать и фиксировать лживое и правдивое поведение респондентов.
VIII UR Lying набор данных
Ученые университета “University of Rzeszow” Л. Матур и М. Й. Матарич собрали набор данных «UR Lying Dataset» (Набор данных обмана Университета Жешува) [8]. Общедоступный набор видеоданных содержит 107 видеороликов (44 правдивых видео, 63 обманчивых видео). В экспериментах участвуют 29 респондентов. Средняя продолжительность каждого видео составляет 23 минуты. Все записи были собраны в условиях надежного освещения и верных точек съемок камеры, а также с незначительными искажениями изображения.
Представленные базы данных обнаружения обмана собирались с использованием различных модальностей. В таблице I показаны существующие наборы данных по обнаружению обмана.
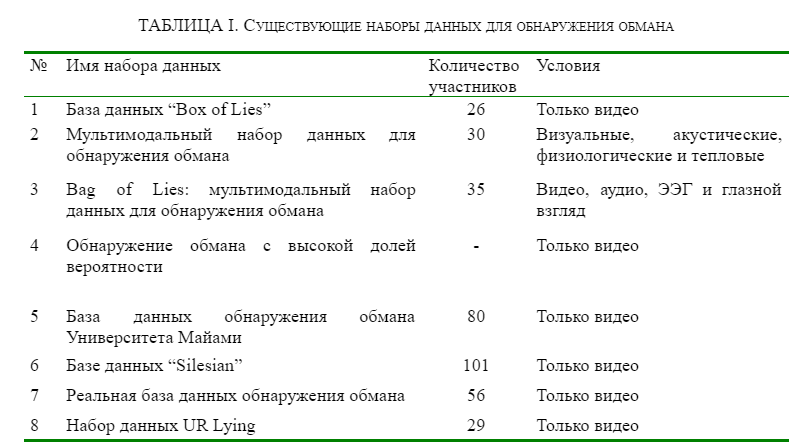
Многие из наборов данных основаны на одной методологии и имеют определенные искажения, что создает увеличение набора данных, ведущее к неправильным выводам и неэффективным результатам [3]. Многие наборы данных собираются и анализируются на основе разных сценариев и различных ситуаций. В таблице II приведены результаты исследований (процент точности) и стратегии сбора данных, которые использовались при первичной выборке информации.

Таким образом, в таблице 1 приведены 8 наборов модальных данных, включающие аудио, видео, ЭЭГ, термо модальности. В основном наборы данных собирались на основе реалистичного сценария, средняя точность составляла 70-80 процентов. В таблице 2 показаны стратегии сбора данных и результаты, которые исследователи получили с этими наборами данных. Исходя из этих таблиц, можно заключить, что эффективно проводить только сбор медиаданных, так как в режиме реального времени будет сложно проводить сбор данных о терме, ЭЭГ и т.д. Однако отмечается, что существует очень мало медиаданных для обучения модели ИИ.
Следует отметить в целом, что проведенные исследования представленных наборов данных рекомендуют следующее: общие характеристики видео (например, длительность) и оценки качества видео в целом (например, четкость изображения) должны быть согласованы и взаимосвязаны для правильного восприятия с целью избежания субъективных оценок. В частности исследователями подчеркивается, что записи с более высокой вероятностью лжи (“High-Stakes Deception Detection Based on Facial Expressions”), как правило, оценивались как более правдивые, тогда как записи с низкой вероятностью лжи были оценены как менее правдивые. Исследования целевой аудитории (“База данных обнаружения обмана Университета Майами”) также подтвердили этот вывод. Более того, для определения точных результатов необходимо включить больше характеристик в анализ аудио-видео материала [5].
Данные исследования показали также, что обман можно предвидеть без опоры на респондента в целом [9]. Анализ видеоизображения с помощью программы ИИ, в котором используется технология визуального точечного определения высокого и низкого уровней, по существу лучше обнаруживает обман по сравнению с респондентами. При этом когда используется дополнительные данные из стенограммы звука, прогноз обмана может быть также более вероятным.
Необходимо отметить, что общедоступных баз данных по обнаружению обмана мало, и это определенная проблема для исследователей в этой области. В рамках будущей работы мы планируем создать набор данных для обнаружения лжи. И в этой связи, важно подчеркнуть, что эффективнее было бы расширить базу данных медиаданными, собранными на основе гипотетических сценариев с вербальной или невербальной фиксацией правды и лжи, тогда можно получить больше предварительно помеченных данных. Следует отметить также, что необходимо проведение экспериментов по тестированию респондентов для выявления правдивых и ложных высказываний в режиме реального времени. Запись данных экспериментов позволит собрать набор медиаданных для выявления различных характеристик по определению аномального поведения респондента с целью выявления ложных высказываний.
Ссылки
[1] Felix Soldner, Verónica Pérez-Rosas, and Rada Mihalcea. 2019. Box of Lies: Multimodal Deception Detection in Dialogues. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1768–1777, Minneapolis, Minnesota. Association for Computational Linguistics.
[2] Verónica Pérez-Rosas, Rada Mihalcea, Alexis Narvaez, and Mihai Burzo. 2014. A Multimodal Dataset for Deception Detection. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14), pages 3118–3122, Reykjavik, Iceland. European Language Resources Association (ELRA).
[3] Viresh Gupta, Mohit Agarwal, Manik Arora, Tanmoy Chakraborty, Richa Singh and Mayank Vatsa, "Bag-of-Lies: A Multimodal Dataset for Deception Detection," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019, pp. 83-90, https://doi.org/10.1109/CVPRW.2019.00016
[4] Lin Su and Martin D. Levine, "High-Stakes Deception Detection Based on Facial Expressions," 2014 22nd International Conference on Pattern Recognition, 2014, pp. 2519-2524, https://doi.org/10.1109/ICPR.2014.435
[5] Lloyd E. Paige, Jason C. Deska, Kurt Hugenberg, et al. Miami University deception detection database. Behav Res 51, 429–439 (2019). https://doi.org/10.3758/s13428-018-1061-4
[6] Radlak, Krystian & Bożek, Maciej & Smolka, Bogdan. (2015). Silesian Deception Database: Presentation and Analysis. 29-35. https://doi.org/10.1145/2823465.2823469
[7] Pérez-Rosas, Verónica & Abouelenien, Mohamed & Mihalcea, Rada & Xiao, Yao & Linton, CJ & Burzo, Mihai. (2015). Verbal and Nonverbal Clues for Real-life Deception Detection. 2336-2346. https://doi.org/10.18653/v1/D15-1281
[8] Leena Mathur and Maja J. Matarić, "Unsupervised Audio-Visual Subspace Alignment for High-Stakes Deception Detection," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 2255-2259, https://doi.org/10.1109/ICASSP39728.2021.9413550
[9] Zhe Wu, Bharat Singh, Larry S. Davis, and V. S. Subrahmanian. 2018. Deception detection in videos. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI'18/IAAI'18/EAAI'18). AAAI Press, Article 207, 1695–1702
НАО «Университет Нархоз»
ул. Жандосова, 55 г. Алматы, Казахстан, 050035

