
1.
Разработка
методов и алгоритмов по детектированию аномального поведения респондента
Разработаны новые методы и алгоритмы для детектирования аномального поведения
респондента. Важным этапом было создание и тестирование различных ИИ-алгоритмов,
которые были интегрированы в общий фреймворк для анализа поведения респондента.
В частности, был разработан комплексный алгоритм, включающий следующие
компоненты:
Извлечение аудиопризнаков
Анализ аудиоданных
является важным элементом для детектирования аномального поведения. В рамках
проекта использовались следующие методы:
Извлечение видеопризнаков
Анализ видеоданных
позволяет выявлять невербальные признаки аномального поведения. В проекте
использовались следующие методы:

Рисунок 1. 68 точек функции определения мимики лица
Извлечение текстовых признаков
Анализ текстовых данных,
включая письменную и устную речь, является ключевым элементом в детектировании
ложных высказываний. В рамках проекта были разработаны следующие методы:
2. Обучение моделей искусственного интеллекта на основе разработанных алгоритмов и тестирование полученных результатов
1. Описание данных
Данные представляют собой мультимодальные последовательности, включающие:
- Аудио: матрицы фиксированной длины, содержащие 96 характеристик.
- Текст: текстовые данные, преобразованные в числовые последовательности с помощью токенизации.
- Видео: временные последовательности, содержащие координаты 68 точек.
Обучающая выборка разделена на тренировочную (80%) и тестовую (20%) подвыборки.
Для каждого набора данных был выполнен процесс предварительной обработки, включающий:
Обучение моделей
Для обучения моделей использовались следующие архитектуры
нейронных сетей:
2. Архитектура модели
Для обработки данных используется комбинированная архитектура, включающая:
- LSTM-слой для аудио-данных.
- Полносвязный слой для текстовых данных.
- LSTM-слой для обработки видеоданных.
- Dropout-слои для регуляризации.
- Объединение выходов через слой concatenate.
- Выходной слой с сигмоидной активацией для бинарной классификации.
Модель оптимизируется с ис
пользованием функции потерь binary_crossentropy и оптимизатора Adam
3. Процесс обучения
4. Результаты тестирования
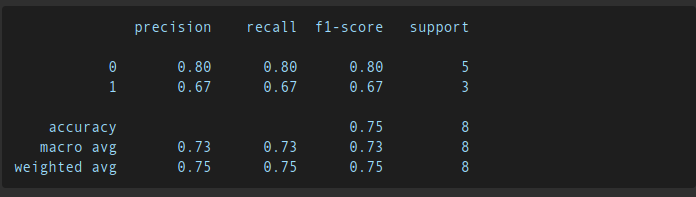
Модель тестировалась на отдельной выборке. Ключевые метрики:
- Точность (Accuracy): 75%.
- F1-метрика: 0.67.
Классификационный отчет:
5. Результаты на реальных данных
При тестировании на реальных данных модель продемонстрировала уверенную работу, подтверждая свою эффективность. Предсказания модели соответствовали ожидаемым результатам в большинстве случаев, что свидетельствует о хорошей способности модели к генерализации на данных, не представленных в обучающей выборке.
Матрица ошибок (Confusion Matrix) — показывает количество правильных и ошибочных классификаций для каждого класса.

Диаграмма метрик — отображает значения Precision, Recall и F1-Score для анализа производительности модели.

Пример результата с тестовыми данными:
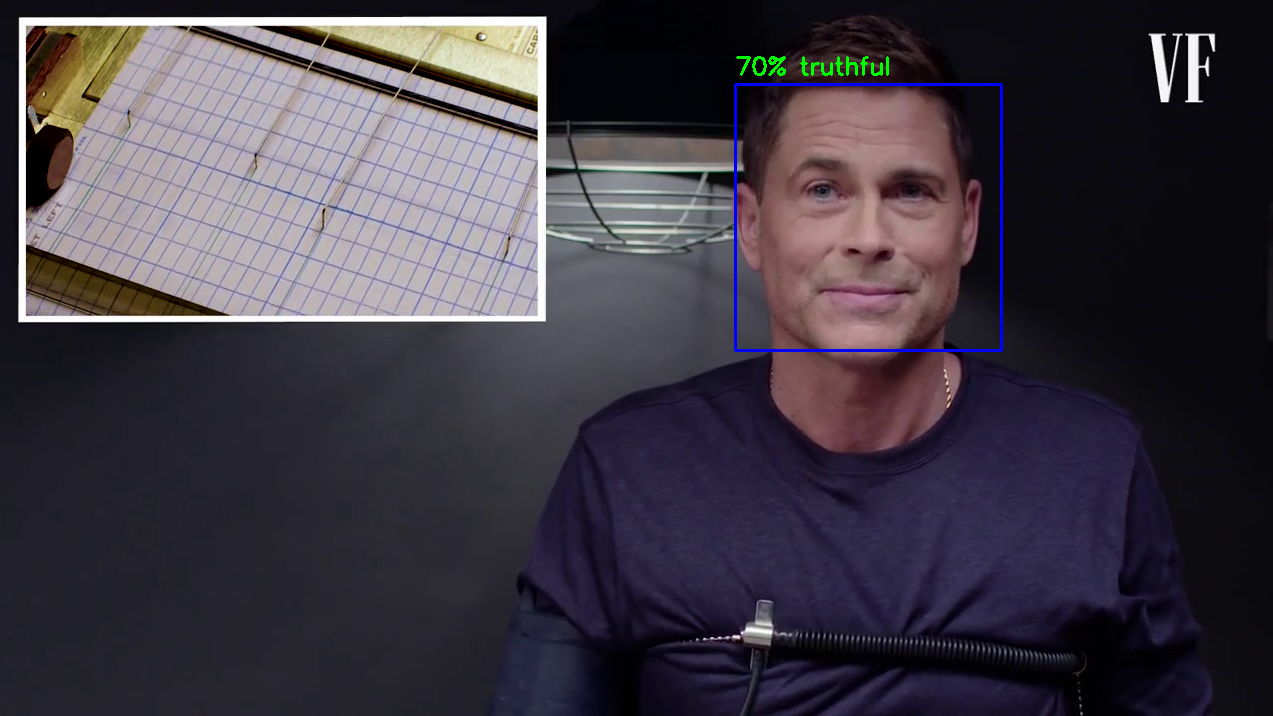
Пример результата с реальными данными:

6. Выводы
Модель успешно обучена на мультимодальных данных и продемонстрировала высокие показатели на тестовой выборке. Точность классификации составила 75%, что подтверждает эффективность предложенной архитектуры для обработки и анализа мультимодальных данных. Результаты на реальных данных дополнительно подчеркивают надежность и применимость модели в практических сценариях.
3. Создание веб-сервиса по обнаружению аномального поведение респондента
Описание выполненных работ. В рамках проекта был разработан веб-сервис для детектирования
обманчивого поведения респондентов. Работы включали в себя:
Примененные методы и технологии:
В результате проделанных работ был создан функциональный веб-сервис, предоставляющий пользователям возможность загружать видео для анализа и получать процентную оценку правдивости респондента. Система обеспечивает точную и быструю обработку данных, демонстрируя высокую надежность и удобство использования благодаря контейнеризированной архитектуре.
Ссылка на веб-сервис НАО «Университет Нархоз»
ул. Жандосова, 55 г. Алматы, Казахстан, 050035

