
Извлечение характеристик
помогает уменьшить объем избыточных данных из набора данных. В конечном итоге
сокращение объема данных помогает построить модель с меньшими машинными
затратами, а также увеличивает скорость этапов изучения и обобщения в процессе
машинного обучения.
Характеристики из видео данных (видеофрагменты) - это числовые
представления визуальной информации в видео, такой как цвета, текстуры, формы,
движения и объекты. Видеофрагменты могут быть извлечены на разных уровнях
детализации, таких как уровень пикселя, уровень кадра или уровень сегмента.
Объекты на уровне пикселей фиксируют необработанные значения интенсивности
каждого пикселя, в то время как объекты на уровне кадра фиксируют глобальные
характеристики каждого кадра, такие как гистограммы или края. Объекты на уровне
сегментов фиксируют локальные характеристики каждого сегмента, такие как
участки или области.
После того, как видеофайлы будут собраны и сохранены, следующим шагом будет
предварительная обработка данных для получения соответствующих характеристик, которые
можно использовать для обнаружения обмана. Это включает использование методов
компьютерного зрения и обработки естественного языка для извлечения выражения
лица, языка тела, речевых паттернов и других соответствующих характеристик из
видеофайлов.
Правильное хранение и
предварительная обработка видеофайлов имеет решающее значение для обеспечения
надежности данных и их пригодности для использования в задачах обнаружения
обмана. Извлечение полезных характеристик из видео имеет решающее значение для
многих приложений компьютерного зрения, включая отслеживание объектов,
распознавание действий и поиск видео на основе контента. Для извлечения характеристик из видео данных
использовались библиотеки языка Python.
Шаги предварительной
обработки данных включают:
Загрузка
и предварительная обработка аудио:
аудиофайлы извлекаются через библиотеку Librosa. Аудиоданные загружаются из
видеофайлов, преобразуются в форму сигнала, а затем преобразуются в
среднечастотные коэффициенты кепстрала (MFCC) с помощью функции librosa.feature.mfcc.
Это обеспечивает представление аудиоконтента в видео.
Звуковые характеристики
Звуковая модальность дает представление о речевых паттернах и вокальных
сигналах, связанных с обманом. Следующие шаги были выполнены для извлечения характеристик
из аудио данных:
a) преобразование видео в аудио: видеоклипы сначала преобразуется из модуля
moviepy.editor в аудиофайлы с помощью класса videofileclip. Это позволяет
извлекать аудиосигналы из видео.
б) загрузка аудио: библиотека librosa используется для загрузки аудиофайлов
и получения аудиоданных и частоты дискретизации. Функция Librosa.load считывает
аудиофайл и возвращает аудиоданные в виде временных рядов и частоты
дискретизации, на которую записан звук.
c) извлечение MFCC: низкочастотные кепстральные коэффициенты (MFCC) - это
широко используемые звуковые характеристики, которые фиксируют спектральные
характеристики звукового сигнала. Librosa.feature.mfcc функция применяется к аудиоданным, используя
частоту дискретизации в качестве параметра для вывода функций mfcc. MFCC
получается путем деления аудиосигнала на частотный диапазон и расчета
кепстральных коэффициентов.
Загрузка и предварительная обработка текста: текстовые характеристики извлекаются через
библиотеку PyTesseract. В наборе реальных данных для каждого кадра в видео код
преобразует кадр в оттенки серого, выполняет оптическое распознавание символов
(OCR) с помощью pytesseract и объединяет полученный текст. Этот шаг фиксирует
текстовую информацию в видеозаписях. В первую базу данных (Real Life Trial Data) включена запись в
видеозаписях. Текстовые описания из»
экспериментального набора данных «были выделены с помощью» Speech-to-Text
API", предоставленного Google. API преобразования речи в текст может
распознавать более 125 языков и их вариантов, поэтому он использовался для
получения текстовых описаний видеозаписей на казахском и русском языках.
Объединение текста: Текст
из каждого кадра объединяется, образуя единое текстовое представление для всего
видео. Это сводное текстовое представление служит входом в текстовую ветку
модели.
Загрузка и предварительное редактирование видео: элементы видео извлекаются
через библиотеку dlib. Код использует детектор лица для обнаружения лиц в
каждом кадре видео. Затем он использует предиктор формы, чтобы получить
ориентацию лица. Эти ориентации лица представляют особенности изображения и
дают представление о выражениях лица и движениях.
Видео
характеристики
Видеомодальность фиксирует выражения лица, движения головы и другие
визуальные сигналы, связанные с обманом. Чтобы извлечь характеристики из видео, были выполнены следующие действия:
a) распознавание лиц:
библиотека dlib используется для идентификации лиц в каждом видеофрагменте. Функция
Dlib.get_frontal_face_detector возвращает объект детектора лица, который может
обнаруживать мимику лица в изображении или видеофрагменте.
б) определение точки
отсчета: после определения лица, функция dlib.shape_predictor используется для
прогнозирования ориентации лица. Shape_predictor_68_face_landmarks.dat файл
меток содержит готовые модели для прогнозирования 68 ориентаций на лице.
Определение ориентации лица Dlib 68 точек-это алгоритм компьютерного зрения,
который определяет 68 ориентиров лица, такие как глаза, нос и рот.
c) получение ориентиров:
для каждого идентифицированного лица берутся координаты 68 ориентиров лица и сохраняются в виде видеофрагментов. Эти
эталонные координаты предоставляют ценную информацию о мимике и движении.
На рисунке ниже показан
пример 68-точечной модели Dlib. Там можно увидеть точки от 1 до 68.

Рисунок 1. Функция определения мимики лица
Важно
отметить, что шаги по предварительной обработке и извлечению характеристик,
описанных выше, применяются к вводящим в заблуждение и реалистичным видеозаписям.
Получая соответствующие характеристики от обоих типов видео, модель может
исследовать закономерности, связанные с обманом, и делать точные прогнозы.
По результатам
исследования выделены характеристики, представленные на рисунке 2.
В частности, были
получены отдельные аудио-и видео характеристики.
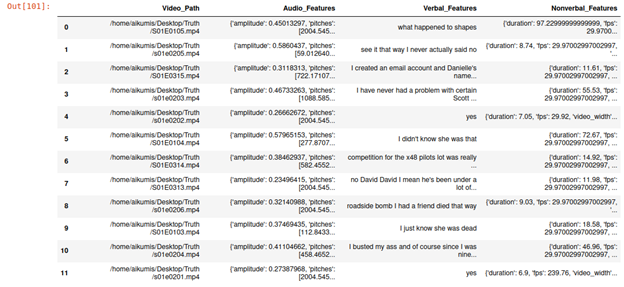
Рисунок 2. “Features data frame” таблица характеристик
НАО «Университет Нархоз»
ул. Жандосова, 55 г. Алматы, Казахстан, 050035

