
1.
Проектирование и создание инфраструктуры хранения данных
Была спроектирована и создана инфраструктура хранения данных на AWS (Amazon Web Services): Cloud BD и облачное пространство для последующего доступа к данным. Эта инфраструктура позволит эффективно импортировать и экспортировать наборы данных, включая аудио, видео, изображения и другие типы данных, обеспечивая удобный доступ к ним [1].
AWS (Amazon Web Services) - это облачная платформа, предоставляемая компанией Amazon. AWS предлагает широкий спектр облачных услуг, включая вычислительные ресурсы, хранение данных, базы данных, аналитику, машинное обучение, и многое другое [2].
AWS является наилучшим выбором по созданию облачного хранилища для задач искусственного интеллекта (ИИ). AWS предлагает масштабируемую инфраструктуру, которая легко расширяется по мере роста объемов данных и требований ИИ-задач. Высокая доступность и надежность AWS гарантируют, что данные всегда доступны и защищены от потерь. Системы безопасности AWS обеспечивают конфиденциальность и целостность данных, а также соответствуют строгим стандартам безопасности. AWS обладает высокой производительностью благодаря своей передовой технологической инфраструктуре, что позволяет обрабатывать и анализировать большие объемы данных ИИ-задач. При этом AWS предлагает гибкость в выборе соответствующих ресурсов и оптимизации процессов. Интеграция с другими сервисами и системами является одним из преимуществ AWS, что обеспечивает гладкое взаимодействие и обмен данными между различными приложениями и компонентами. Наконец, AWS предоставляет высококачественную поддержку клиентов, включая оперативное реагирование на запросы и проблемы, обеспечение технической поддержки и восстановление данных. Исходя из всех этих факторов, можно сделать вывод, что AWS обладает комплексным набором функций и превосходит других облачных провайдеров в создании облачного хранилища для задач искусственного интеллекта.
При проектировании инфраструктуры хранения данных использовались компоненты AWS: корзины S3 и AWS Lambda:
• S3 (Simple Storage Service) - это служба хранения объектов, которая предоставляет высокомасштабируемое, надежное и долгосрочное хранение данных в облаке. S3 бакеты используются для организации и хранения данных в виде объектов. Они могут содержать различные типы файлов, включая аудио, видео, изображения и другие. S3 обеспечивает высокую доступность данных и предлагает различные функции для управления доступом и обработки данных.
• AWS Lambda - это служба вычисления в облаке, которая позволяет запускать код без необходимости управления серверами. AWS Lambda позволяет создавать функции (фрагменты кода), которые могут реагировать на различные события и выполнять операции обработки данных или взаимодействия с другими сервисами AWS. В контексте этой задачи, AWS Lambda может использоваться для обработки импорта и экспорта наборов данных, а также для выполнения различных операций с этими данными.

Рисунок 1
. Архитектура
облачного хранилища (Cloud BD и облачное пространство)
В созданной архитектуре (Рис. 1), для хранения
и обработки данных и обеспечения потока работы между пользователями и системой
AWS, было создано пять корзин S3 и реализована функция Lambda. Первая корзина,
названная "Audio", включающая 948 аудио данных (Рис. 2), предназначена для загрузки аудиофайлов. Она служит
основным хранилищем аудиоданных, которые могут быть загружены пользователями.
Кроме того, настроена репликация данной корзины, что обеспечивает создание ее
дубликата для повышения отказоустойчивости и доступности данных. Вторая
корзина, "Video", включающая 617 видео данных (Рис. 3), предназначена для загрузки видеофайлов. Она
аналогична корзине "Audio" и служит для хранения видеоданных,
загруженных пользователями. Также была настроена репликация этой корзины, чтобы
обеспечить сохранность данных и их доступность в случае сбоев. Третья корзина,
"Output", предназначена для загрузки обработанных файлов. В этой корзине функция Lambda сохраняет обработанные данные. Четвертая корзина - это копия (репликация) первой корзины, а пятая корзина - это копия второй корзины. Связь между пользователями и системой AWS осуществляется
через выбор одной из двух корзин: "Audio" или "Video".
Пользователи могут загружать соответствующие файлы в выбранную корзину, и после
этого функция Lambda автоматически обрабатывает эти файлы и сохраняет
результаты в корзину "Output". Обработанные файлы в корзине
"Output" затем доступны для дальнейшего использования другими
пользователями. Такая архитектура обеспечивает эффективный поток данных и
обработки, а также обеспечивает отказоустойчивость и доступность данных
благодаря репликации корзин.
Рисунок 2. Корзина S3 с аудио данными
Рисунок 3. Корзина S3 с видео данными
В созданную инфраструктуру хранения данных был внедрен алгоритм ИИ. Разработка алгоритма искусственного интеллекта (Face Detection Algorithm, FDA) для обнаружения лиц респондентов является важной составляющей обработки данных. FDA повышает эффективность работы и уменьшает объем данных, хранящихся в облачном хранилище. Целью этого кода является обнаружение человеческих лиц в видеопотоке и сохранение кадров с обнаружением человеческого лица в качестве выходных данных. Алгоритм реализован с использованием библиотеки Mediapipe и OpenCV, с использованием языка программирования Python.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1.
K. Venkatachalam, M. Perumal (2019), "Designing a Cloud Storage Architecture: Understanding Storage Technology", International Journal of Advanced Research in Computer Science and Software Engineering.
2.
Jinesh V., Sajee M. (2014), Overview of Amazon Web Services.
2.
Создание и агрегирование наборов данных из различных источников в созданную инфраструктуру хранения данных
Обзор набора данных
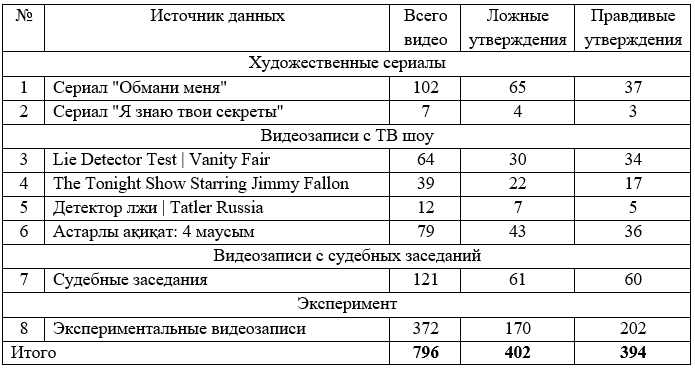
Были созданы 4 набора данных: первый набор данных включает в себя судебные заседания «Муниципальный суд Провиденса, штат Род-Айленд», «The supreme court: decided cases (2022)»; второй набор данных: детективные художественные сериалы, использующие технологию детектирования лжи: «Обмани меня», «Я знаю твои секреты»; третий набор данных включает в себя видео с ТВ шоу: «The Tonight Show Starring JimmyFallon», «Lie Detector Test | Vanity Fair», «Детектор лжи», «Астарлы ақиқат: 4 маусым»; четвертый набор данных состоит из видеозаписей собранных посредством интервью. Набор данных из судебных заседаний состоит из 121 видео (61 ложных и 60 правдивых утверждений). Набор данных включает в себя 56 участников (21 женщина и 35 мужчин), возраст которых составляет от 16 до 60 лет.

Рисунок1. Примеры скриншотов, показывающих мимику и жесты рук в судебных заседаниях.
Средняя продолжительность видеозаписей в представленном наборе данных составляет 28,0 секунды. Важно отметить, что средняя продолжительность ложных видео составляет 27,7 секунды, а для правдивых видеозаписей, продолжительность составляет 28,3 секунды. Это говорит о том, что существует некоторое различие во временных характеристиках между различными типами видеозаписей в наборе данных. Для создания данного набора данных использовались парсеры с открытых интерактивных медиа-источников, в которых были доступны записи судебных заседаний. Это позволило наблюдать и подтверждать как ложное, так и истинное поведение в судебных процессах.
Следующий набор данных включает в себя художественные детективные сериалы, всего 109 видеозаписей. Сериал «Обмани меня»: с 1 сезона было собрано 27 отрывков. Из них 12 правдивых. Размер: 37,5МБ. Средняя продолжительность каждого отрывка 30,08 секунд. Общая продолжительность: 361 секунд. Ширина кадра: 624. Высота кадра: 352. Частота дискретизации аудио: 44,100 кГц. 15 лживых. Размер: 31,1МБ. Средняя продолжительность каждого отрывка 21 секунд. Общая продолжительность: 315 секунд. Ширина кадра: 624. Высота кадра: 352. Частота дискретизации аудио: 44,100 кГц.
Сериал: Я знаю твои секреты. Гладиатор. Общее количество собранных файлов: 7. Размер: 29,9МБ. Средняя продолжительность каждого отрывка 12,6 секунд. Общая продолжительность: 88 секунд. Ширина кадра: 1024. Высота кадра: 576. Частота кадров: 25 кадров/с. Частота дискретизации аудио: 48 кГц.
Еще одним источником данных стали видеозаписи с ТВ шоу: Lie Detector Test | Vanity Fair 64 видеозаписей, The Tonight Show Starring Jimmy Fallon 39 видеозаписей, Детектор лжи | Tatler Russia 12 видеозаписей, Астарлы ақиқат: 4 маусым 79 видеозаписей. Всего 194 видеозаписей из низ 102 лживых, 92 правдивых утверждений.
Следующим источником данных стали экспериментальные видеозаписи, снятые с помощью интервьюирование респондентов. Участники отвечали на предварительно подготовленные вопросы на казахском и русском языках. Видеозаписи были сделаны в близком ракурсе, чтобы точно отслеживать мимику и движения каждого участника.
Эксперимент - интервью состоит из трех этапов. Первый этап проводился в форме интервью: вопрос - ответ. Второй этап содержит анализ интервью верификаторами. Третий этап включает сбор, агрегирование и анализ данных.
Первый этап: интервью.
Процедура проведения интервью: 30 студентов делятся на 3 группы по 10 человек. Первой группе студентов предложено ответить на все вопросы правдиво, другой группе - дать ложные ответы, а третья группа будут отвечать на вопросы в свободной форме.
Длительность интервью: 120 минут.
Список вопросов:
Простые и прямые вопросы:
1. Вы живете с родителями?
2. У вас есть друзья?
3. Вы когда-нибудь предавали друзей?
4. Вы всегда готовитесь к урокам заранее?
5. Вы когда-нибудь совершали кражи?
Простые вопросы:
1. Чем вы занимаетесь в свободное время?
2. Сколько времени у вас уходит на подготовку занятий?
3. Сколько времени вы тратите на бездельничество ?
4. Вы когда-нибудь предлагали выполнить домашнюю работу за кого-то другого в обмен на что-то конкретное от него?
Проективные вопросы:
1. Как вы думаете, почему люди врут?
2. Как вы думаете, правильно ли списывать ?
3. Как вы относитесь к одногруппникам, которые списывают друг у друга?
Провокационные вопросы:
1. Что вы больше всего цените в своих друзьях?
2. Что является вашим главным недостатком?
3. Что мешает вам быть полностью счастливым?
Негативные вопросы:
1. Вы ведь тоже иногда ленитесь и пытаетесь списать домашнее задание у друга?
2. Вам же тоже трудно вставать по утрам, правда?Вопросы - ловушка:
1. Если ваши родители позвонят в университет и им скажут что вас исключили. Что тогда вы скажете?
2. Если бы вы были преподавателем, каким образом вы бы оценивали студентов?
Второй этап: верификация.
Процедура проведения верификации: верификаторы анализировали материалы записей с интервью, выявили правдивые и ложные ответы с учетом невербального компонента.
Верификаторами были установлены 64 ложных, 70 правдивых записей.
Длительность верификации: 120 минут.
Третий этап: сбор, агрегирование и анализ данных по интервью и верификации.
Процедура проведения сбора, агрегировании и анализа данных
Из процесса интервью было снято 81 видео, которые были агрегированы и собраны в ответ на каждый вопрос. Агрегировано из видеозаписей 170 ложных утверждений, 202 правдивых утверждения, всего 372 видеозаписи. Средняя продолжительность каждого отрывка составляет 5-10 секунд. Важно отметить что, видеозаписи были сняты в экспериментальной среде, в хорошо освещенной аудитории.
Из 4 наборов данных было собрано в общем количестве 796 видеозаписей. На основе этих данных был создан «Экспериментальный набор данных», содержащий 402 ложных, 394 правдивых утверждений для дальнейших задач исследования.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Pérez-Rosas,
V., Abouelenien, M., Mihalcea, R., & Burzo, M. (2015). Deception Detection
using Real-life Trial Data. Proceedings of the 2015 ACM on International
Conference on Multimodal Interaction (pp. 59-66). ACM.
doi:10.1145/2818346.2820758
Soldner,
F., Pérez-Rosas, V., & Mihalcea, R. (2019). Box of Lies: Multimodal
Deception Detection in Dialogues. Proceedings of the 2019 Conference of the
North American Chapter of the Association for Computational Linguistics: Human
Language Technologies (pp. 1768–1777). Minneapolis, Minnesota: Association
for Computational Linguistics. doi:10.18653/v1/N19-1175
Wu,
Z., Singh, B., Davis, L., & Subrahmanian, V. (2018). Deception Detection in
Videos. Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.1609/aaai.v32i1.11502
3. Разметка
и извлечение характеристик из данных
Разметка видео данных
Представлена методология разметки, описание данных, а также статистика по разметке и
размеченных кадров, что дает полное представление о процессе разметки видео
данных для задачи детектирования истинных и ложных высказываний.
Цель
Целью данной разметки видео
данных было создание качественной и точной разметки для последующего обучения
моделей ИИ, способных детектировать истинные и ложные высказывания в
видеофайлах. В ходе работы учитывались особенности специализированного научного
направления - искусственного интеллекта и информационных технологий.
Методология разметки
В этом разделе представлена
методология, которая была использована для разметки видео данных в рамках
проекта по детектированию истинных и ложных высказываний.
· Инструменты разметки: Для разметки видео данных был использован инструмент "VGG Image
Annotator (VIA)" версии 2.0.8. Этот инструмент предоставляет удобные
средства для создания разметки на кадрах видео и позволяет сохранять аннотации
в удобном формате для последующего анализа и обучения моделей машинного
обучения.
·
Кодировка: Для обозначения истинных и ложных высказываний в видео была
использована следующая система кодировки:
"1"
для истинных высказываний: Этот код использовался для отметки кадров, на
которых респондент произносил истинное утверждение или факт.
"0"
для ложных высказываний: Этот код использовался для кадров, на которых
респондент произносил ложное утверждение или факт.
Эта кодировка
была выбрана для стандартизации процесса разметки и дальнейшего обучения
моделей машинного обучения. Каждый кадр видео был размечен в соответствии с
указанными кодами, что позволило создать аннотированный датасет для дальнейших
исследований и разработок.
Описание данных
Для выполнения задачи разметки
видео данных в рамках проекта по детектированию истинных и ложных высказываний
был использован разнообразный набор данных, включающий в себя следующую
информацию:
· Продолжительность
видео: Средняя продолжительность видеозаписей в данном наборе данных
составляет 28,0 секунд. Важно отметить, что средняя продолжительность ложных
видео составляет 27,7 секунд, а для правдивых видеозаписей - 28,3 секунды.
· Информация о
художественных сериалах:
· Сериал
"Обмани меня" содержит 27 видеозаписей из 1 сезона, включая 12 правдивых и 15 ложных
утверждений. Средняя продолжительность каждого отрывка составляет 30,08 секунд,
общая продолжительность - 361 секунда.
· Сериал
"Я знаю твои секреты" представлен 7 видеозаписями с общей продолжительностью 88 секунд.
Средняя продолжительность отрывка - 12,6 секунд.
· Информация о видеозаписях с
ТВ шоу:
· Lie
Detector Test | Vanity Fair содержит 64 видеозаписи.
· The
Tonight Show Starring Jimmy Fallon содержит 39 видеозаписей.
· Детектор
лжи | Tatler Russia включает 12 видеозаписей.
· Астарлы ақиқат: 4 маусым включает 79
видеозаписей. Всего в этих источниках данных представлено 194 видеозаписи, из
которых 102 являются ложными, а 92 - правдивыми утверждениями.
· Информация о
экспериментальных видеозаписях:
В
рамках эксперимента было снято 81 видео в ответ на каждый вопрос. Эти
видеозаписи агрегировались, и общее количество составило 372 видеозаписи.
Средняя продолжительность каждого отрывка составляет 5-10 секунд. Важно
отметить, что данные видеозаписи были сняты в экспериментальной среде с
хорошим освещением.
· Судебные
заседения: Набор
данных включает в себя 121 видеофайл, из которых 61 содержат ложные
высказывания, а 60 - правдивые утверждения.
Разметка
Итоговый экспериментальный набор
данных включает 796 видеозаписей.
· Истинные высказывания: 394
· Ложные высказывания: 402
В результате выполнения разметки
видео данных для проекта по детектированию истинных и ложных высказываний были
достигнуты следующие важные моменты:
· Качественная
разметка данных. Мы успешно провели разметку большого объема
видеофайлов, аннотируя их как содержащие истинные или ложные высказывания. Эта
разметка была выполнена в соответствии с кодировкой, что позволило
стандартизировать процесс и обеспечить качественную аннотацию.
· Разнообразный
набор данных. Мы использовали разнообразные источники данных,
включая художественные сериалы, ТВ шоу, экспериментальные записи, что обогатило
наш набор данных и позволило создать экспериментальный набор данных, содержащий
402 ложных и 394 правдивых утверждений. Это многообразие источников данных
сделало наш проект более репрезентативным и обширным.
· Значимость
разметки для проекта. Разметка видео данных является фундаментальным
этапом для обучения и тестирования моделей машинного обучения в рамках проекта
детектирования истинных и ложных высказываний. Надежность и точность разметки
оказывает непосредственное воздействие на качество и эффективность создаваемых
моделей. Поэтому качественная разметка данных является ключевым компонентом
нашего проекта.
НАО «Университет Нархоз»
ул. Жандосова, 55 г. Алматы, Казахстан, 050035

